池上 有希乃 その他のプログラミング経歴
主な研究
モードレス日本語入力, 2012年2月~2013年2月
英数字/日本語モード切替を自動で行うモードレス入力の研究. キーボードから入力されたローマ字列から n-gram ベースの識別モデルを用いて日本語らしい部分のみ仮名変換を行い, それ以外はローマ字のままにします. これによって英数モードとかなモードの入力モードを切り替える手間がなくなります. 先行研究では識別に文字表記 n-gram のみを用いていたのに対して, 本研究では文字種(大文字/小文字/数字/記号) n-gram や曖昧性のない英語辞書を用いることで 99.71% の精度のモードレス入力が可能となりました.
- 論文:
- Programming language: Python, C++
- Middleware/Library: MeCab, LIBLINEAR, marisa-trie
- OS: Mac OSX
情報信憑性判定システム, 2011年4月~8月

Twitter の投稿の情報信憑性を数値化して出力するシステム. Latent Dirichlet Allocation (LDA) によって投稿を話題ごとにクラスタリングし, それぞれの投稿の意見の極性 (肯定/否定) を推定し, 肯定/否定の割合によって情報信憑性を数値化します.
- 論文:
- Yukino Ikegami, Kenta Kawai, Yoshimi Namihira, Setsuo Tsuruta.
Topic and Opinion Classification Based Information Credibility Analysis on Twitter.
SMC 2013, pp. 4676–4681, 2013.
- Yoshimi Namihira, Naomichi Segawa, Yukino Ikegami, Kenta Kawai, Takashi Kawabe, Setsuo Tsuruta.
High Precision Credibility Analysis of Information on Twitter.
SITIS 2013, pp. 909–915, 2013.
- 特許: 特願2013-002269 情報判定装置、情報判定方法、およびプログラム
- Programming language: Python, PHP, R
- Middleware/Library: MeCab, MySQL, GibbsLDA++, Classias, EasyBotter
- OS: Linux (Ubuntu)
句単位照応解析, 2012年8月
句単位での照応関係を同定する研究. 例えば,
「君もそろそろ部長だね」と常務から言われました。
あの話は一体なんだったんでしょう
という文章のあの話が何を指しているかを当てる手法の研究です. こうした照応関係は対話にて発生することがありますが, これまでの照応解析はあくまでも単語単位での照応関係を扱うもので, 句単位での照応関係が行わなれていなかったので, 日立製作所横浜研究所インターンにて取り組みました.
- 論文:
- Programming language: Python
- OS: Linux (CentOS)
悩み相談用対話エージェントシステム, 2012年3月~2014年2月
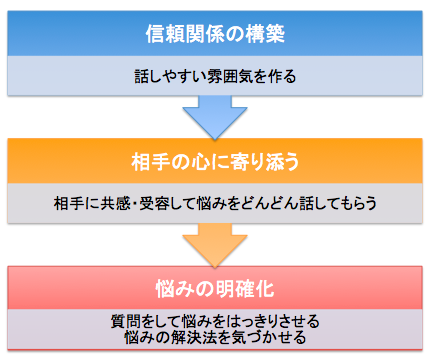
対話を通して相談者自身が問題解決の気づきを得られるように支援するエキスパートシステム. 心理学分野の知見やテクニックをコンピュータで実現することを目標としています. 自然言語処理では照応解析や感情推定, 談話要約の技術が使われています.
- 論文:
- Yukiko Yamamoto, Tetsuo Shinozaki, Yukino Ikegami, Setsuo Tsuruta.
Context respectful counseling agent virtualized on the web.
World Wide Web, pp. 1–24, 2015.
- Testuo Shinozaki, Yukino Ikegami, Estele Bissay, Setsuo Tsuruta.
Applying Context Respectful Summarization to Counseling Agent for the Japanese.
SITIS 2013, pp. 916–923, 2013.
- 特許: 特願2013-109854 内省支援装置、内省支援方法、内省支援プログラム、対話装置、対話方法および対話プログラム
- 紹介記事: 文脈尊重型カウンセリングエージェント||東京電機大学
- Programming language: Python, C++
- Middleware/Library: MeCab, CaboCha, ASA, ML-ASK
- OS: Windows, Mac OSX, Linux (Vine Linux)
その他
Stanford University Coursera Machine Learning Course, 2016年4月~5月
スタンフォード大学のオンライン講義サービスCourseraのMachine Learningコースの課題として, ロジスティック回帰やニューラルネットワークなどを実装しました.
Stanford Coursera Machine Learning Course Certificate
- Programming language: Octave
- OS: Mac OSX
現代/歴史的仮名遣における平仮名表記の曖昧性評価, 2011年10月~2012年1月
かな漢字変換における同音異義語による誤変換の解消手段として歴史的仮名遣表記に着目しました. そこで歴史的仮名遣表記のかな漢字変換における有用性を評価するため, 日本語辞書 NAIST-Japanese Dictionary の読みを歴史的仮名遣化し, 平仮名表記の曖昧性を情報エントロピーなどの尺度で現代仮名遣表記と評価するプログラムを作成しました. そして評価の結果, 歴史的仮名遣表記の方が有意に曖昧性が低いことがわかりました.
- Programming language: Python, R
- OS: Mac OSX
マルチモーダル質問応答システム, 2011年9月
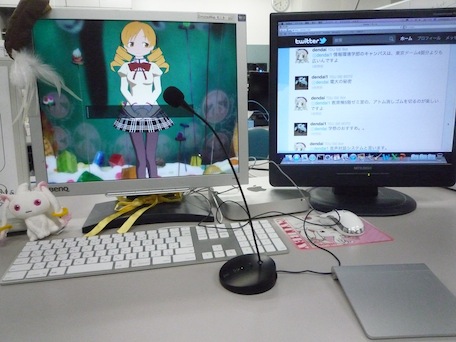
音声対話による質問応答システム. 返答時に 3D アバターが返答の内容に沿った感情表現を行います. 例えば, 質問の答えが残念なものは暗い喋り方でユーザに答えます. 音声対話ツールキット MMDAgent をベースに, 音声認識用辞書の語彙拡張, 質問検索, 感情分類処理を追加しました. 質問検索には Yahoo!知恵袋のデータを用いました. 音声認識用の辞書にも Yahoo!知恵袋の質問文 (約50MB) から句単位(フレーズベース)によって構築しました.
- Programming language: Python, PHP, C++
- Middleware/Library: MMDAgent, The SRI Language Modeling Toolkit (SRILM), MeCab
- OS: Windows
Twitter アカウント推薦システム, 2010年10月~2011年1月
Twitter のログを解析して利用者が興味を持ちそうな Twitter アカウントを推薦するシステム. 共通の知人がいたり共通の話題が多い人に興味を持つだろうという仮定をもとに, 推薦基準として Latent Dirichlet Allocation (LDA) によるトピックの類似度や利用者のリプライ頻度による重み付けをした共通フォロワー数などを用いました.
- Programming language: Python, PHP
- Middleware/Library: Apache, MeCab, MySQL, GibbsLDA++, EasyBotter, Maxent
- OS: Windows
学園祭案内用質問応答システム, 2010年9月
 →
→  →
→ 
初期画面 → 処理中 → 結果出力
ゲーム用コントローラのボタンを押すと音声とテキストによって大学および学園祭の情報を案内するシステム. 学園祭では親子連れで来る方が多いため, 子供にも楽しめるように入出力インターフェースに視覚 (GUI), 聴覚 (音声合成), 触覚 (ゲーム pop'n music 用コントローラ) を使うものを選びました. システムの処理系の他に画面インターフェースの設計・開発も行いました.
- Programming language: PHP, JavaScript, C#
- Middleware/Library: Apache, Ajax, MeCab, MySQL, AquesTalk2
- OS: Windows